The most common type of CAPTCHA was first invented in 1997, but the term CAPTCHA (for Completely Automated Public Turing Test to Tell Computers and Humans Apart) was coined only in 2000 by Luis von Ahn, Manuel Blum, Nicholas Hopper and John Langford of Carnegie Mellon University.
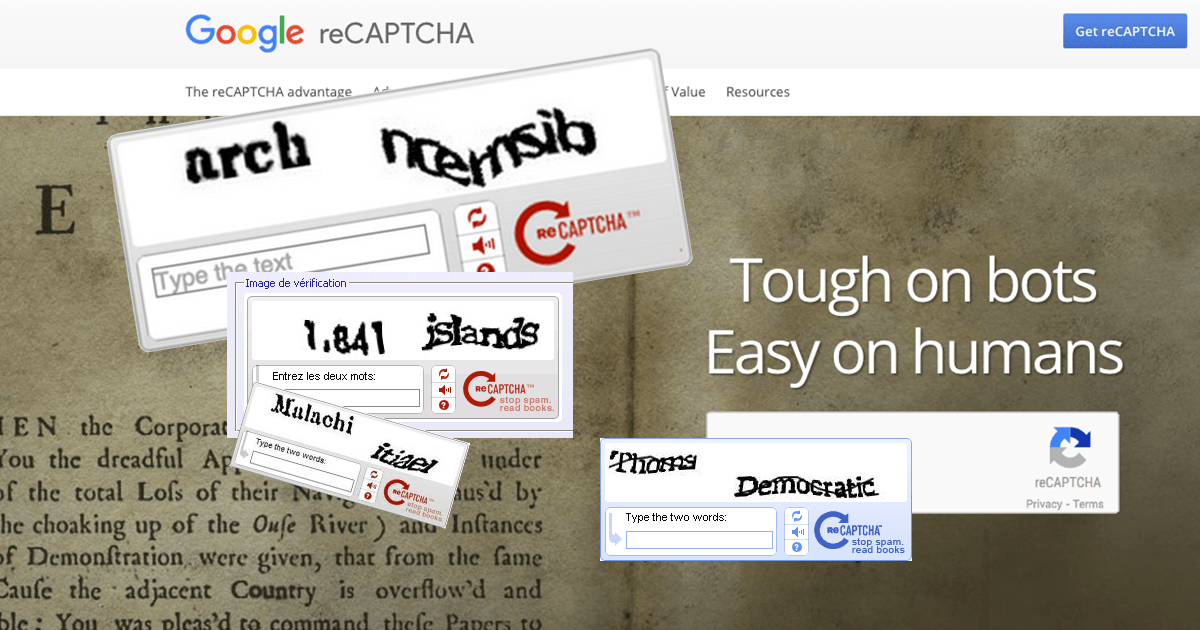
Synonymous of security on the internet by creating barrier against spammers and robots, the famous captcha codes are those distorted characters and camouflaged that you are asked to identify in order to have access to a site, validate a transaction or download something. Any internet user came across with one of these at least once in life.
In 2009 the Captcha was acquired by Google, and then the new technology ReCAPTCHA gained an extra function.
They Realized that, although spending just a few seconds to type the CAPTCHA, humans were taking hundreds of thousands of hours typing in more than 100 million CAPTCHAs every day.
So they had the ideia to maximise all this Human thinking time, entering in the captcha codes, words that Google’s computers can not decipher when scanning books and maps.
In the scanning process about 20% of the texts can not be identified by the computer. The great advantage of having all these 100% recognized text, is turn all books and newspapers scanned on searchable archives.
The CAPTCHA is working to decipher the 20% of the archives of the New York Times and Google Books books where more than 13 million articles in full Have Been archived, dating from 1851 to the present day.
Only in the first five years of the project, the human recognition deciphered and transcribed the equivalent of 17,600 books.
This is security working for knowledge.
Learn more about reCAPTCHA:

